G13GAM -- Game Theory
Alpha-beta pruning
Alpha-beta pruning is a potentially hard concept because, at one level,
it's counter-intuitive.
We can understand that we don't want to look at bad moves, why
is it that we don't want to look at good moves?
The first partial answer is that this is the other side of the same
coin -- a move that is good for me is bad for you.
The second partial answer is that it isn't that we don't want to know
about good moves, rather that it's their existence not their details
that matter.
The third partial answer is that we don't need so much good moves
as good enough moves;
it is because `good enough' moves are much easier to find than `good' moves
that this technique makes a huge improvement to any game-playing program.
What is alpha-beta pruning?
[The name is essentially completely arbitrary -- the two variables
concerned in a computer program happened to be called alpha and beta,
and we might just as well have had fred-jim pruning, p-q pruning or
foo-bar pruning.]
 When we are called upon to analyse a position, we will be given two
`levels', alpha and beta.
These are the `floor' and `ceiling', respectively, of the range of
values our caller is interested in.
Think of the beta level as representing a value which is `good enough';
we'll worry later about what `good enough' really means, and also
about what the alpha level means.
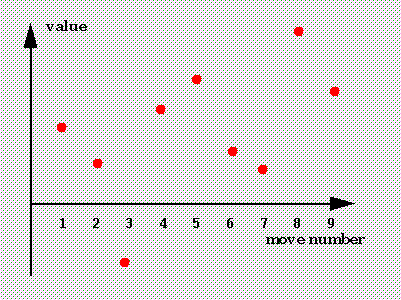
Let us suppose that a full analysis would give us the picture shown to
the right:
we see that of the nine possible moves, moves 1, 4, 5 and 9 are reasonably
good, moves 2, 6 and 7 are so-so, move 3 is a disaster, and move 8 is
the star move we would like to find.
These values could be found by static evaluation, or by dynamic [recursive]
evaluations looking deeper in the game tree.
When we are called upon to analyse a position, we will be given two
`levels', alpha and beta.
These are the `floor' and `ceiling', respectively, of the range of
values our caller is interested in.
Think of the beta level as representing a value which is `good enough';
we'll worry later about what `good enough' really means, and also
about what the alpha level means.
Let us suppose that a full analysis would give us the picture shown to
the right:
we see that of the nine possible moves, moves 1, 4, 5 and 9 are reasonably
good, moves 2, 6 and 7 are so-so, move 3 is a disaster, and move 8 is
the star move we would like to find.
These values could be found by static evaluation, or by dynamic [recursive]
evaluations looking deeper in the game tree.
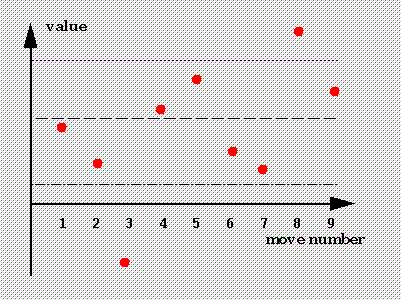
The second picture shows what could happen for various possible beta levels.
The top [dotted] line shows a high level.
In this case, almost no gain is made;
none of the first seven moves is `good enough', but move 8 at last goes over
the line, and we can return its value.
If the line had been a little higher, then no move would have been
over the line, nothing would have been gained, and we would have had to
do a full evaluation of all nine moves.
The middle [dashed] line shows a lower beta level.
In this case, move 4 is already `good enough'.
We do not need even to glance at moves 5 to 9.
We can stop the analysis immediately, and return the value of move 4.
The bottom [mixed] line shows an even more favourable situation;
here the very first move is `good enough', and we can return its value
without glancing at moves 2 to 9.
This can be a huge saving of time.
We've saved 8/9 of the analysis already;
but it can be better than this in the context of dynamic analysis, for we
can make similar savings at every level of the tree, equivalent [in this
example] to having a computer which is potentially 9×9×9×...
times faster, and the deeper we look, the bigger the advantage.
Note that the advantage is maximised by having the beta level as low
as possible, and by having `good enough' moves as early in the
list of moves as possible.
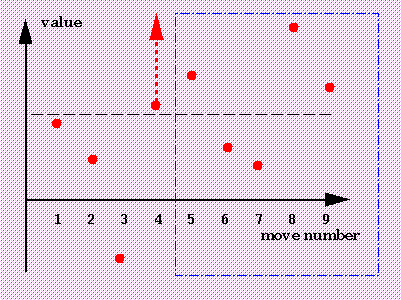
Note however that once pruning has taken place, we are no longer returning
the true value of a position.
The third picture shows this in the context of the middle [dashed]
beta level.
The true value of this position is the value of the best move, move 8.
But we are returning the value of move 4, the first `good enough' move;
we don't know whether or not later moves will be even better, so all we
can say is that the true value of this position is at least the
value of move 4.
This is shown by the arrow.
The [potentially huge] savings made by pruning the moves in the blue box
are [slightly] offset by the loss of information and the return of a
lower bound rather than a true value.
Very often, the lower bound is all we need, and the pruning is pure gain.
This leaves two questions.
Where do the alpha and beta levels come from?
And what is the alpha level for?
They come from whoever asked us to analyse this position;
we in turn will pass them on to any subsidiary [`dynamic'] analysis.
Because positions are evaluated from the point of view of the player to move,
they will be `inverted' when they are passed on -- the caller's `ceiling'
is the callee's `floor', and vice versa.
So the alpha level, the `floor', will become the beta level, the ceiling,
for the subsidiary analysis;
the higher we can make the floor, the lower will be the resulting ceiling,
and so the more efficient will be that analysis.
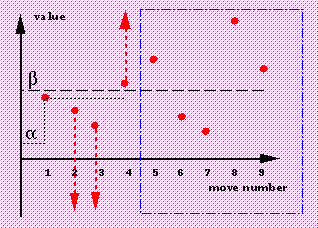
The next picture, left, shows this in action.
We have inherited alpha and beta levels from our `parent'.
After evaluating move number 1, we are no longer interested in moves that
are worse than this, so we can raise the floor to the corresponding value.
Moves 2 and 3 now fall below this floor;
these values come from the `children' discovering moves above their
beta level, so all we can say is that these values are upper bounds on the
true values -- but even the upper bounds are below our floor, so we don't
need to know the true values, just that moves 2 and 3 are worse than move 1.
This is indicated by the arrows again;
note that the tops of the arrows are higher than the corresponding dots were
in the previous pictures.
In summary, when we evaluate a move, one of three things will happen:
(a) The value lies between alpha and beta.
In this case, this move is potentially interesting -- it may be the best
move in the position, and its value may be the value of the position
as a whole.
We can raise the value of alpha to match, for we are no longer interested
in exact values of worse moves.
(b) The value is at least beta.
This move is `good enough', and causes a `beta cutoff'.
We return its value as a lower bound for the true value without
bothering to evaluate the remaining moves.
This value will, after inversion, be below the floor for the `parent'.
The move causing the cutoff is sufficient to `refute' the move leading
to this position.
(c) The value is at most alpha.
This move has been refuted, possibly by a beta cutoff in the `child'.
This value is an upper bound, not the true value, which may be much worse,
but this will not affect the value of the current position.
Value of alpha-beta
Some [rather ignorant!] programmers treat alpha-beta pruning as an
`optional extra', a modest bonus that makes searching slightly
more efficient at the expense of sophisticated programming.
Not so!
Its use typically doubles the depth to which the program
can search.
Since the tree is growing exponentially with increasing depth,
this is equivalent to an exponential growth in the speed with
which the program can search.
However, the pruning is seen to full advantage only if
(a) the beta levels are low enough to be interesting, and
(b) the first move tried is often `good enough'.
So much effort has gone in to ensuring that these two conditions hold.
An insight into the help that alpha-beta pruning gives can be had by
imagining that Kasparov is sitting next to you suggesting good moves
to try.
When you are doing well, and when his suggestions are good, you do not
need to consider anything beyond his ideas, and your analysis can be
conducted much more efficiently -- a beta cutoff!
If his suggestions are bad, then you will have to consider other ideas
as well [this is point (b) above!], but even rotten suggestions
do not cost you anything compared with no suggestions at all
If your position is bad, then his suggestions do not [indeed,
cannot] help;
all the evaluations will be too low to cause a cutoff;
but even in this case, his suggestions will raise the floor as far as it
can be raised [if he gives you the best ideas first], so that deeper
analysis will see a lower ceiling and easier cutoffs [this is point
(a) above].
In most lines, with best play [as suggested by Kasparov!], good positions
and bad positions will alternate [my piece up is your piece down!];
alpha-beta pruning causes very quick cutoffs in the good positions,
which is why you can search twice as deeply.
Of course, in real life your computer does not have access to Kasparov;
it has to do the best it can with its own analysis.
Refinements
The `correct' way to use alpha-beta pruning is to start with alpha
set to minus infinity, beta to plus infinity, and to rely on the
natural `raising of the floor', seen above, to make the bounds more
useful.
However, this creates a tension with the observation above that the
pruning works best if the bounds are as tight as possible.
So other strategies are possible.
Essentially, in all of these, we lie to our children about our
proposed alpha-beta bounds.
Our children must, however, tell us the truth, as outlined above:
if the value is between alpha and beta, they must return the correct
value, otherwise they return an upper or lower bound.
Our lies mean that we place the bounds closer than they should have
been, and therefore that the search is more efficient.
The penalty is that sometimes we are caught out.
Even so, we will quite often get away with it;
if the returned value is outside the true bounds, then we only need
the upper or lower bound anyway.
If however it is inside the true bounds but outside the fraudulent bounds,
then we have to ask our children to look again, and to refine their
evaluations.
So, the search is made sometimes more efficient and sometimes less.
Where the balance lies is a matter of pragmatism and experiment.
Once this viewpoint is accepted, then describing this as `lying'
carries unwanted moral overtones.
We should instead re-define the purpose of the analysis as being to
provide a value which is either `guaranteed' or else merely a bound,
as described above.
Then we can ask our children questions with a clear conscience!
Effectively, we are asking of the analysis questions like `In this
position, is White between 1 and 2 pawns up?', and getting answers like
`Yes, White is 1.376 pawns up' or `No, White is at least 2.3 pawns up',
or `No, White is no more than 0.52 pawns up'.
[All of these questions and answers relative to the requested depth
of analysis, of course.]
These questions can be answered much more efficiently than the blunt
`How many pawns up is White?', and the answers are usually, but not
always, sufficient.
When they are not sufficient, we have to ask again, `OK, is White between
2.3 and 3 pawns up', and balance these extra questions against the
extra efficiency.
top of page
E-mail: [my initials] [at] cuboid.me.uk,
home page:
http://cuboid.me.uk/anw.
Copyright © Dr A. N. Walker, 1997, 2016.